
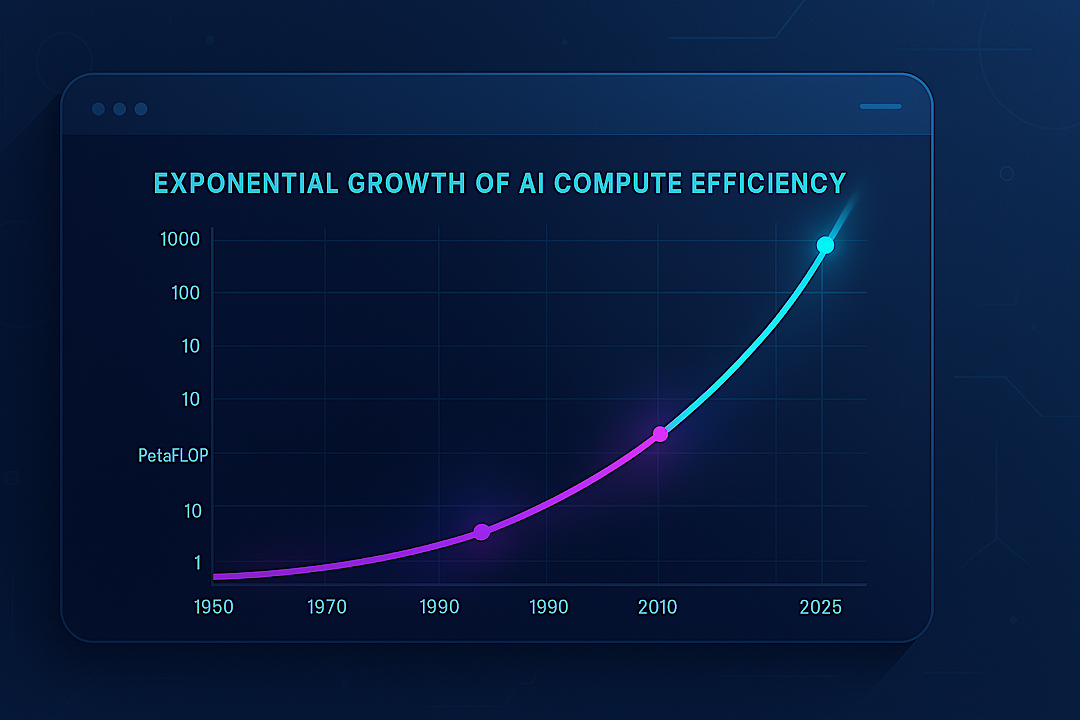

TEKNOLOGI, Perspektif.co.id — Lonjakan efisiensi pelatihan AI kembali menjadi sorotan setelah analisis terbaru Epoch AI menunjukkan percepatan yang jauh lebih agresif dibandingkan perkiraan industri. Temuan ini mencuat ketika riset yang dirilis pada 2025 menegaskan bahwa peningkatan kemampuan model tidak hanya didorong oleh ekspansi infrastruktur, tetapi juga oleh lompatan besar dalam efisiensi algoritmik yang terjadi secara konsisten setiap tahun. Data tersebut memperlihatkan bagaimana komputasi pelatihan AI meningkat secara eksponensial sejak era Perceptron pada 1950 hingga model frontier seperti GPT-4 pada 2023, dengan tren percepatan 4,2 kali lipat per tahun sejak 2010—jauh di atas fase pertumbuhan 1,5 kali lipat pada periode 1950–2010.
Peningkatan efisiensi ini menjadi semakin signifikan setelah peneliti Epoch AI, Anson Ho, menegaskan bahwa sebagian besar lompatan performa tidak berasal dari banyak inovasi kecil, melainkan dari dua terobosan skala besar yang memengaruhi cara model dilatih pada level frontier. Ia menilai bahwa efisiensi pelatihan AI kini meningkat sekitar sepuluh kali lipat setiap tahun, meski interval keyakinannya masih sangat lebar—antara dua hingga lima puluh kali lipat—karena perbedaan metodologi pengukuran.
“Efisiensi pelatihan AI telah meningkat beberapa kali lipat setiap tahun,” tulis laporan tersebut, menyoroti bahwa tren ini terjadi tanpa perubahan arsitektur besar yang terlihat dari luar.
Pernyataan itu diperkuat oleh data yang menunjukkan bagaimana perangkat keras baru seperti Rubin GPU mampu memberikan peningkatan efisiensi hingga 100 kali dibanding generasi sebelumnya, sehingga setiap inovasi algoritmik yang dibangun di atasnya menjadi semakin berdampak. Situasi ini memicu implikasi ekonomi dan geopolitik yang luas, terutama ketika negara-negara seperti Tiongkok berupaya mempercepat pengembangan model AI untuk mengejar ketertinggalan dari Barat.
“Estimasi efisiensi dari Scher 2025 berada di kisaran peningkatan 10x per tahun, meski rentang ketidakpastiannya jauh lebih besar,” ungkap laporan tersebut, menegaskan bahwa arah tren tetap konsisten meski angka pastinya masih diperdebatkan.
Kenaikan efisiensi ini juga mengubah strategi perusahaan teknologi global. Dengan kebutuhan komputasi yang semakin kecil untuk mencapai kemampuan model yang sama, waktu pengembangan dapat dipangkas, biaya infrastruktur berkurang, dan hambatan masuk bagi pemain baru semakin rendah. Kondisi ini terjadi di tengah ekspansi besar-besaran pusat data AI, termasuk kapasitas komputasi 19 GW yang diproyeksikan menopang industri pada 2025—setara dengan investasi puluhan miliar dolar AS atau ratusan triliun rupiah.
“Tidak ada perubahan arsitektur besar yang terlihat, namun efisiensi meningkat karena rutinitas pelatihan yang lebih cerdas dan penanganan data yang lebih baik,” tulis laporan tersebut, menegaskan bahwa kemajuan AI tidak lagi sekadar soal menambah GPU, tetapi mengoptimalkan setiap lapisan proses pelatihan.
Tren ini memperlihatkan bahwa percepatan AI bukan hanya fenomena perangkat keras, melainkan hasil kombinasi inovasi algoritmik, efisiensi data, dan optimalisasi sistem yang bekerja secara simultan. Dengan skala pertumbuhan yang terus meningkat, industri kini menghadapi pertanyaan besar: seberapa cepat AI akan mencapai kemampuan yang mendekati AGI, dan siapa yang akan memimpin perlombaan global ketika efisiensi menjadi faktor penentu?





